Skip to main content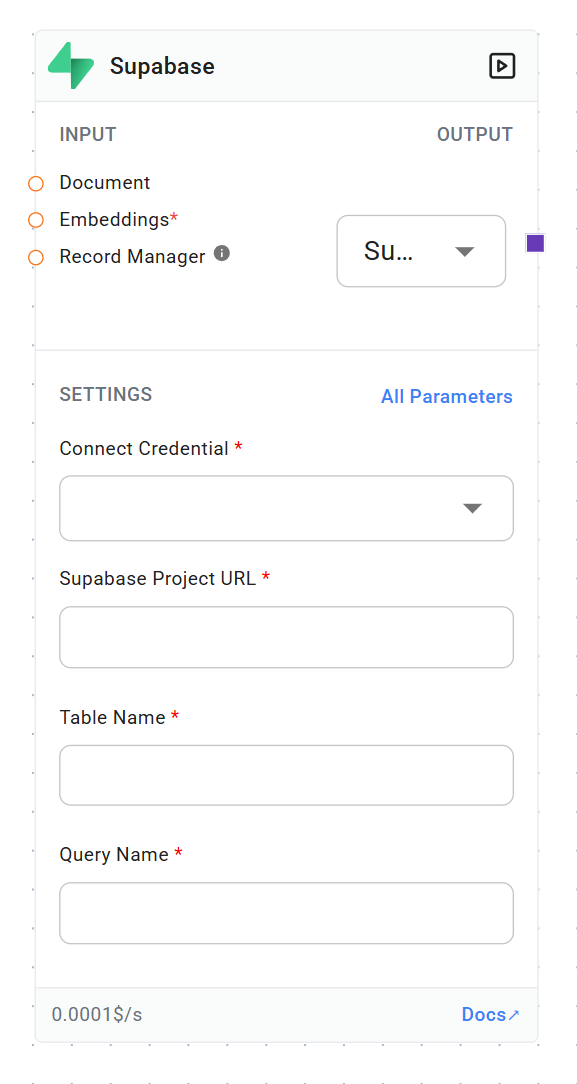
Node Details
-
Name: Supabase_VectorStores
-
Type: Supabase
-
Version: 4.0
-
Category: Vector Stores
Base Classes
-
Supabase
-
VectorStoreRetriever
-
BaseRetriever
-
Document (optional, list)
-
Type: Document
-
Description: List of documents to be embedded and stored
-
Embeddings
-
Type: Embeddings
-
Description: The embedding model to use for converting documents to vectors
-
Record Manager (optional)
-
Type: RecordManager
-
Description: Keeps track of records to prevent duplication
-
Supabase Project URL
-
Type: string
-
Description: URL of the Supabase project
-
Table Name
-
Type: string
-
Description: Name of the table in Supabase to store vectors
-
Query Name
-
Type: string
-
Description: Name of the query to use for similarity search
-
Supabase Metadata Filter (optional)
-
Type: json
-
Description: JSON object for filtering results based on metadata
-
Supabase RPC Filter (optional)
-
Type: string
-
Description: Query builder-style filtering, overrides metadata filter if set
-
Top K (optional)
-
Type: number
-
Description: Number of top results to fetch (default: 4)
-
MMR Parameters (optional)
- Various parameters for Maximal Marginal Relevance search
Outputs
-
Supabase Retriever
-
Type: Retriever
-
Description: A retriever object for querying the vector store
-
Supabase Vector Store
-
Type: VectorStore
-
Description: The Supabase vector store object
Credentials
-
Credential Name: supabaseApi
-
Required Parameters: supabaseApiKey
Functionality
-
Upsert: Adds or updates documents in the vector store
-
Delete: Removes documents from the vector store
-
Search: Performs similarity or MMR search on the stored vectors
Usage
This node is particularly useful in workflows that require:
-
Storing and managing large amounts of textual data as vector embeddings
-
Performing semantic similarity search on document collections
-
Building retrieval-augmented generation systems
-
Creating knowledge bases or document retrieval systems
Note
The node includes additional functionality for handling record management, batch upserts, and error handling for null ID values. It’s designed to work seamlessly with Supabase’s vector storage capabilities and integrates well with other LangChain components.