Skip to main content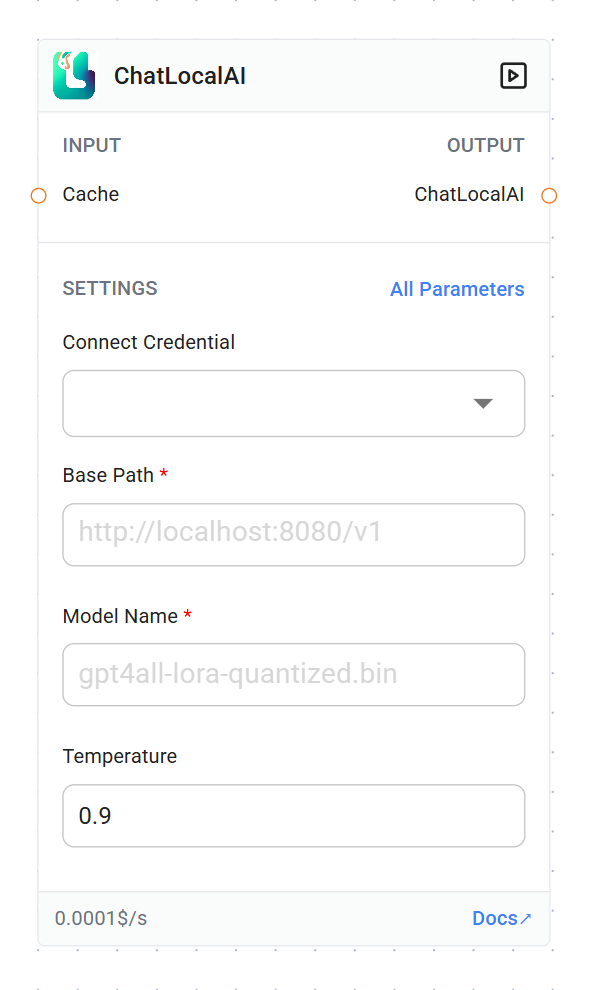
Node Details
- Name: ChatLocalAI
- Type: ChatLocalAI
- Version: 2.0
- Category: Chat Models
Base Classes
- ChatLocalAI
- BaseChatModel
- [ChatOpenAI base classes]
Base Classes
- ChatLocalAI
- BaseChatModel
- [ChatOpenAI base classes]
Parameters
Credential (Optional)
Parameters
Credential (Optional)
-
Cache (optional)
- Type: BaseCache
- Description: Caching mechanism for the model responses
-
Base Path (required)
-
Model Name (required)
- Type: string
- Placeholder: gpt4all-lora-quantized.bin
- Description: The name of the local model file to be used
-
Temperature (optional)
- Type: number
- Default: 0.9
- Step: 0.1
- Description: Controls the randomness of the model’s output
-
Max Tokens (optional)
- Type: number
- Step: 1
- Description: The maximum number of tokens to generate in the response
-
Top Probability (optional)
- Type: number
- Step: 0.1
- Description: Limits the token selection to a subset of tokens with a cumulative probability
-
Timeout (optional)
- Type: number
- Step: 1
- Description: Maximum time (in milliseconds) to wait for a response from the model
Initialization
The node initializes a ChatOpenAI instance with the provided parameters. It uses the LocalAI API key (if provided) and sets up the model with the specified base path, temperature, max tokens, and other optional parameters.
Usage
This node can be used in workflows where a local LLM is preferred over cloud-based solutions. It’s particularly useful for:
- Maintaining data privacy by keeping all processing local
- Reducing latency in environments with high-speed access to local resources
- Customizing and fine-tuning models for specific use cases
- Operating in environments with limited or no internet connectivity
Output
The node returns an initialized ChatOpenAI model instance, which can be used for generating responses in a chat-like interaction pattern.
Notes
- Ensure that the LocalAI server is properly set up and running at the specified base path.
- The model file (specified in the Model Name parameter) should be available to the LocalAI server.
- Performance and capabilities may vary depending on the local hardware and the specific model being used.