Skip to main content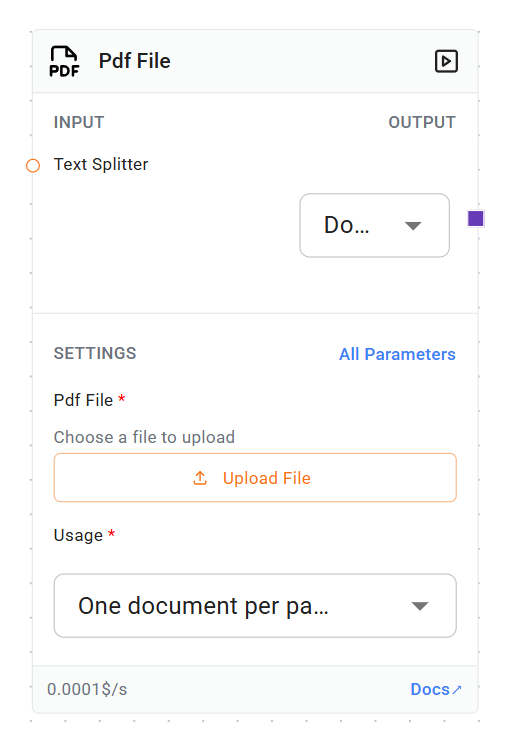
Node Details
- Name: pdfFile
- Type: Document
- Category: Document Loaders
- Version: 1.0
Parameters
-
Pdf File (required)
- Type: file
- File Type: .pdf
- Description: The PDF file(s) to be processed.
-
Text Splitter (optional)
- Type: TextSplitter
- Description: A text splitter to be applied to the extracted text.
-
Usage (required)
- Type: options
- Options:
- One document per page (perPage)
- One document per file (perFile)
- Default: perPage
- Description: Determines how the PDF content is split into documents.
-
Use Legacy Build (optional)
- Type: boolean
- Description: Whether to use the legacy build of the PDF parsing library.
-
Additional Metadata (optional)
- Type: json
- Description: Additional metadata to be added to the extracted documents.
-
Omit Metadata Keys (optional)
- Type: string
- Description: Comma-separated list of metadata keys to omit from the final documents. Use * to omit all default metadata keys.
The node accepts PDF files either as base64-encoded strings or as file references from storage.
Output
The node outputs an array of IDocument objects, each representing a page or a whole PDF file (depending on the Usage setting). Each document contains:
- Page content as text
- Metadata (which can be customized or filtered based on the input parameters)
Functionality
- Loads PDF file(s) from the provided input (either base64-encoded or from file storage).
- Processes each PDF file:
- If Usage is set to ‘perFile’, it creates one document per PDF file.
- If Usage is set to ‘perPage’, it creates one document per page of each PDF file.
- Applies text splitting if a TextSplitter is provided.
- Adds or modifies metadata based on the Additional Metadata input.
- Filters metadata based on the Omit Metadata Keys input.
Use Cases
- Extracting text content from PDF files for further processing or analysis.
- Preparing PDF content for ingestion into vector databases or search engines.
- Splitting large PDF documents into smaller, more manageable chunks.
- Customizing metadata for PDF-sourced documents in a document processing pipeline.
Notes
- The node uses the PDFLoader from the langchain library for PDF parsing.
- It supports both modern and legacy builds of the PDF parsing library, which can be useful for compatibility with different types of PDF files.
- The node is flexible in handling both single and multiple PDF files in one operation.