Skip to main content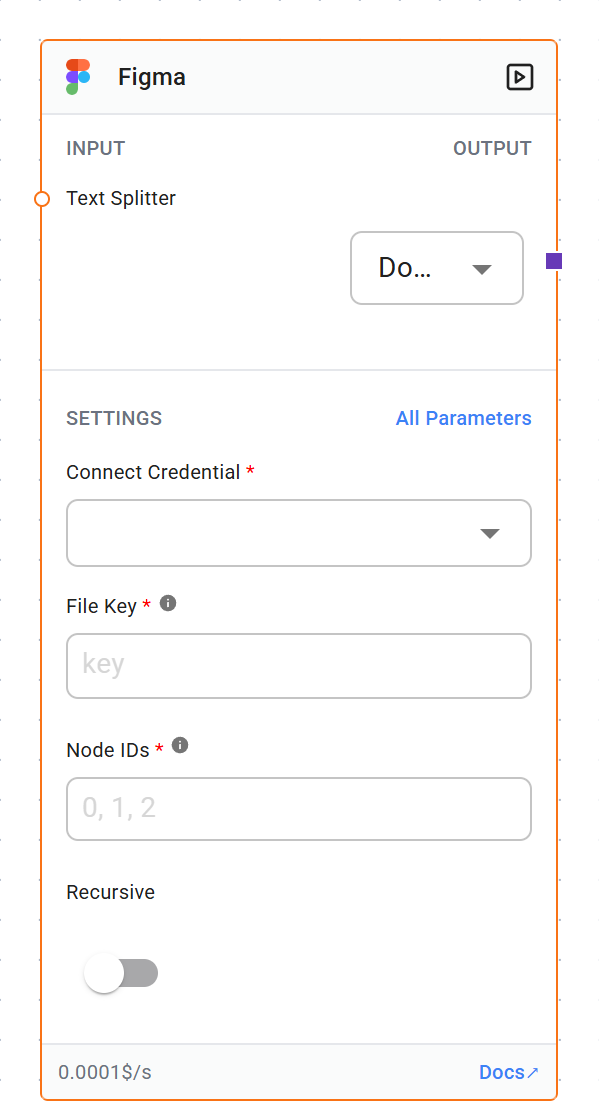
Node Details
-
Name: figma
-
Type: Document
-
Category: Document Loaders
-
Version: 1.0
-
Base Class: Document
Credentials
-
Type: figmaApi
-
Required Parameters:
accessToken: Figma API access token
-
File Key (required)
-
Node IDs (required)
-
Type: string
-
Description: A comma-separated list of Node IDs to extract data from. Node IDs can be obtained using the Figma Node Inspector plugin.
-
Recursive (optional)
-
Type: boolean
-
Description: If set to true, the loader will recursively extract data from child nodes.
-
Text Splitter (optional)
-
Type: TextSplitter
-
Description: A text splitter to process the extracted text. If provided, the loader will split the documents using this splitter.
-
Additional Metadata (optional)
-
Type: json
-
Description: Additional metadata to be added to the extracted documents.
-
Omit Metadata Keys (optional)
-
Type: string
-
Description: A comma-separated list of metadata keys to omit from the final output. Use ’*’ to omit all default metadata keys.
Output
The node outputs an array of IDocument objects, each containing:
-
pageContent: The extracted text content from the Figma node
-
metadata: Associated metadata, which may include:
-
Figma-specific information (e.g., node ID, node type)
-
Any additional metadata provided in the input
-
Metadata may be filtered based on the “Omit Metadata Keys” input
Usage
This node is particularly useful for:
-
Extracting text content from Figma designs for natural language processing tasks
-
Analyzing design elements and structure programmatically
-
Incorporating design information into AI training data
-
Automating documentation processes based on Figma designs
Implementation Details
-
Uses the
FigmaFileLoader from the @langchain/community package
-
Supports optional text splitting using a provided
TextSplitter
-
Allows for customization of metadata inclusion and exclusion
-
Handles authentication through Figma API credentials
Note
Ensure you have the necessary Figma API access and permissions to use this node effectively. Familiarize yourself with Figma’s API usage guidelines and rate limits when working with this loader.