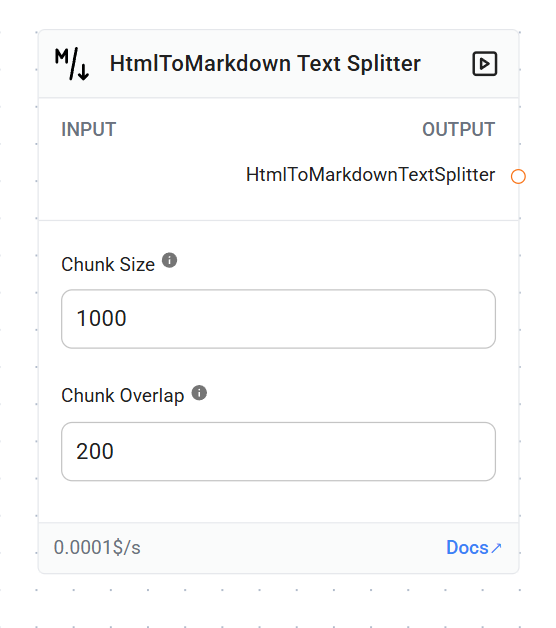
Node Details
- Name: htmlToMarkdownTextSplitter
- Type: HtmlToMarkdownTextSplitter
- Category: Text Splitters
- Version: 1.0
Parameters
-
Chunk Size
- Label: Chunk Size
- Name: chunkSize
- Type: number
- Description: Number of characters in each chunk
- Default: 1000
- Optional: Yes
-
Chunk Overlap
- Label: Chunk Overlap
- Name: chunkOverlap
- Type: number
- Description: Number of characters to overlap between chunks
- Default: 200
- Optional: Yes
Input
The node expects HTML text as input.Output
The node outputs an array of string chunks, where each chunk is a section of the Markdown-converted HTML, split according to the specified chunk size and overlap.How It Works
- The node receives HTML text as input.
-
It uses the
NodeHtmlMarkdown.translate()function to convert the HTML to Markdown. -
The resulting Markdown is then split into chunks using the
MarkdownTextSplitterclass from thelangchain/text_splitterpackage. - The splitting process respects Markdown headers and the specified chunk size and overlap parameters.
Use Cases
- Processing HTML content from web scraping for natural language processing tasks
- Preparing HTML documents for text analysis or summarization
- Converting and chunking HTML-based documentation for improved searchability or processing
Notes
-
This node extends the functionality of the
MarkdownTextSplitterclass to handle HTML input. - The conversion from HTML to Markdown allows for better preservation of document structure compared to plain text splitting.
- The chunk size and overlap can be adjusted to optimize for specific downstream tasks or models.